L'objectif est de rediriger les logs vers un serveur de logs Graylog.
Voici le schéma:
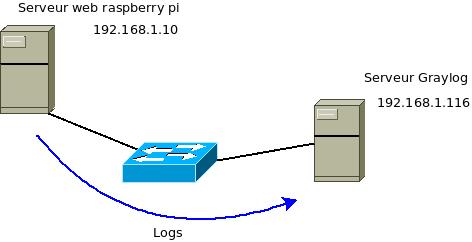
Pour cet article, le serveur web est installé sur un serveur raspberry pi.
Le serveur Graylog est installé sur une distribution Linux Centos.
Configuration de la redirection de logs sur le serveur web
Il faut indiquer la redirection dans la configuration de nginx. On recherche les deux lignes de logs (access_log et error_log), puis on ajoute une ligne pour la redirection.
Les logs seront redirigés vers le port 1514 dans cet exemple.
pi@Raspi:~ $ sudo vi /etc/nginx/nginx.conf
access_log /var/log/nginx/access.log;
error_log /var/log/nginx/error.log;
access_log syslog:server=192.168.1.116:1514,facility=local7,severity=info;
error_log syslog:server=192.168.1.116:1514,facility=local7 warn;
Puis on redémarre le serveur nginx.
pi@Raspi:~ $ sudo systemctl restart nginx.service
pi@Raspi:~ $
Configuration de Graylog pour la réception des logs
Il faut aller dans l'onglet System/Inputs.
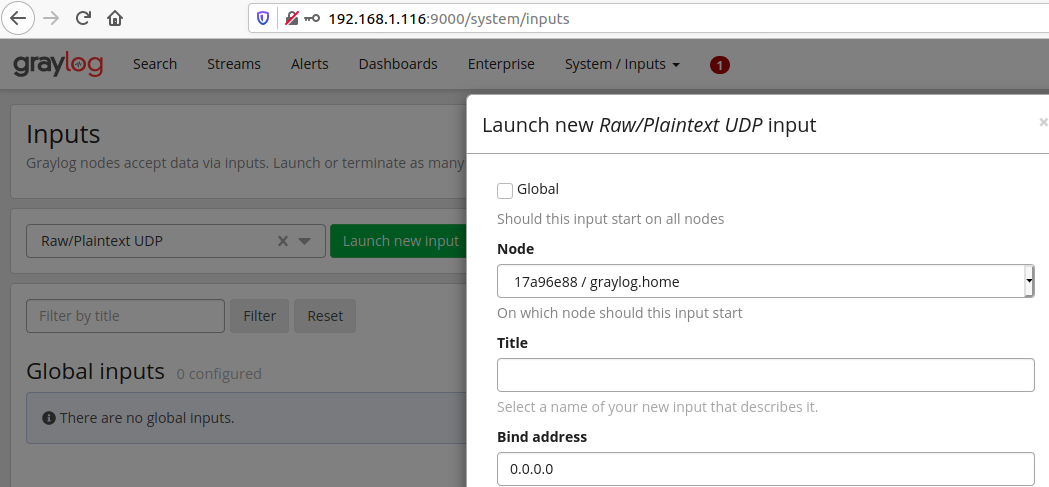
On ajoute une entrée Raw/Plaintext UDP.
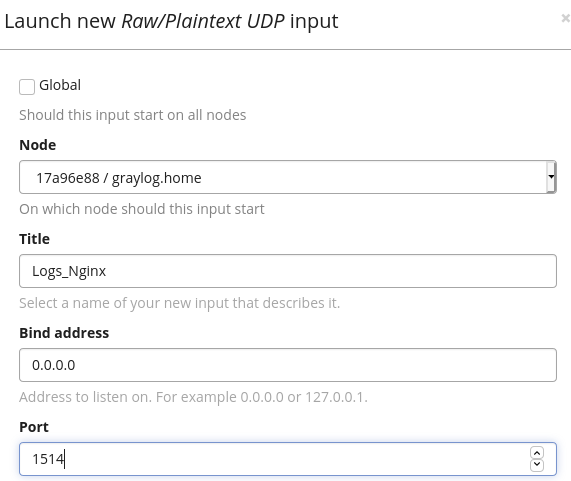
On configure au moins un Titre. Le port sera modifié avec la valeur 1514 et on enregistre la configuration.
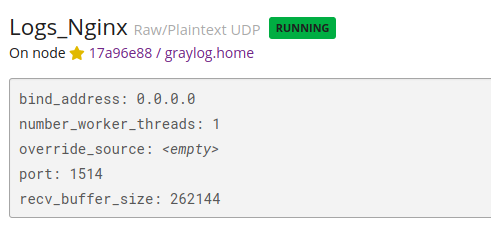
Enfin, on vérifie que l'entrée est active.
Bien sur, il faut ouvrir le port 1514 UDP sur le firewall:
[root@Graylog ~]# firewall-cmd --zone=public --add-port=1514/udp --permanent
success
[root@Graylog ~]# systemctl restart firewalld.service
success
[root@Graylog ~]# firewall-cmd --list-port
9000/tcp 1514/udp
[root@Graylog ~]#
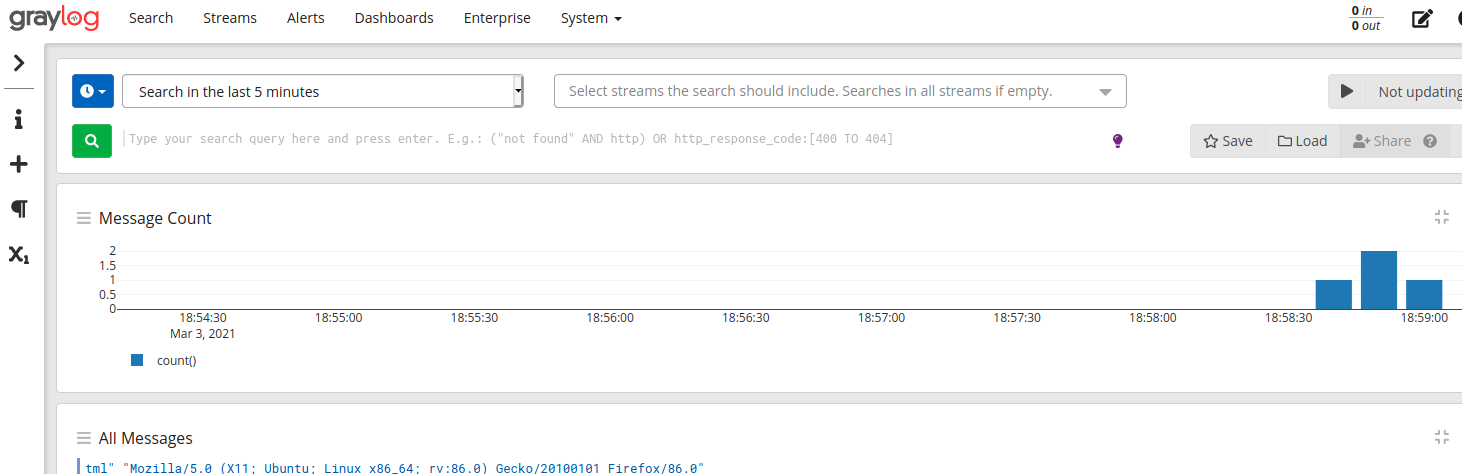
Et voici la visualisation des logs dans l'interface de Graylog.
Configuration de la partie extracteur (extractor) de donnée
Pour pouvoir agréger les données ou les filtrer, il est utile de séparer la ligne de logs en plusieurs champs que l'on pourra nommer.
C'est le role de l'extracteur.
Deux façons de faire :
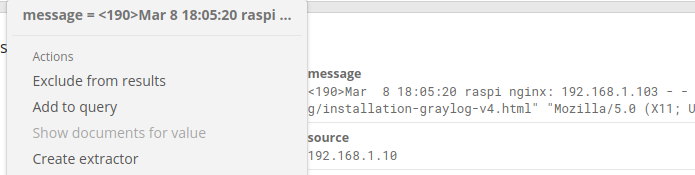
-
en cliquant sur un message puis en sélectionnant "Create extractor",
-
en allant dans le menu System/Inputs puis, pour l'entrée "Logs-nginx", on clique sur le bouton "Manage extractors".
On choisit ici de partir d'un message.
Ensuite, il faut choisir le type d'extracteur de donnée.
On choisit ici un modèle Grok.
Ensuite, il est possible de tester le modèle d'extraction de donnée.
Pour la requête du serveur Nginx, le modèle Grok configuré ici est:
<%{BASE10NUM}>%{MONTH} %{MONTHDAY} %{TIME} %{HOSTNAME} %{WORD:Service}: %{IP:srcIP} - - \[%{HTTPDATE:timestamp}\] "GET %{URIPATH} HTTP/%{NUMBER:httpversion}" %{BASE10NUM:codeHTTP} %{BASE10NUM:bytes} "%{URI}" "%{GREEDYDATA:Navigateur}"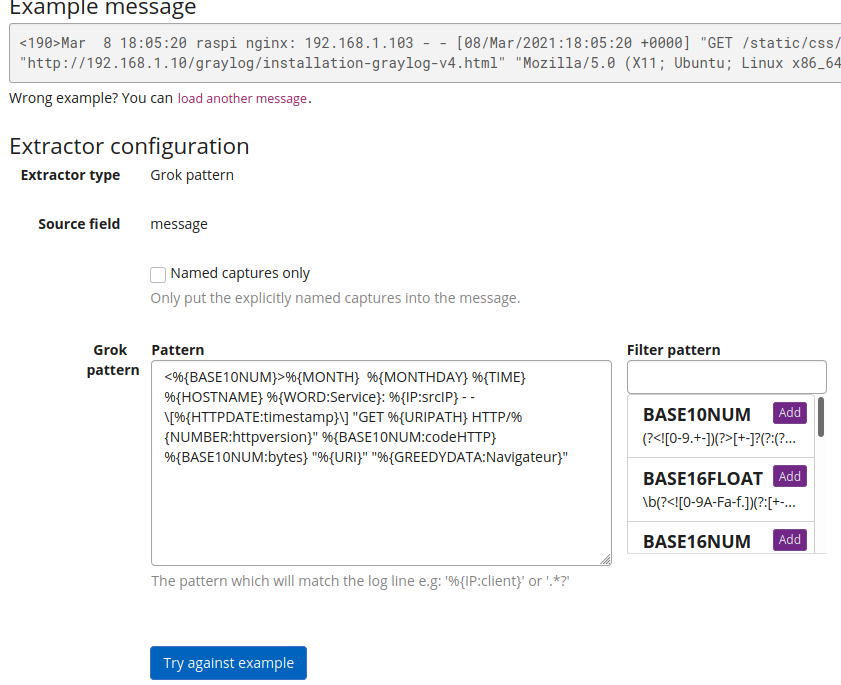
On récupère dans ce modèle les IP sources, les pages chargées, le type de navigateur, ... Et on pourra ensuite faire des tris ou des regroupements sur ces types de donnée.
Enfin, quelques paramètres pour l'application du modèle et notamment la possibilité d'appliquer un filtre sur l'extraction.
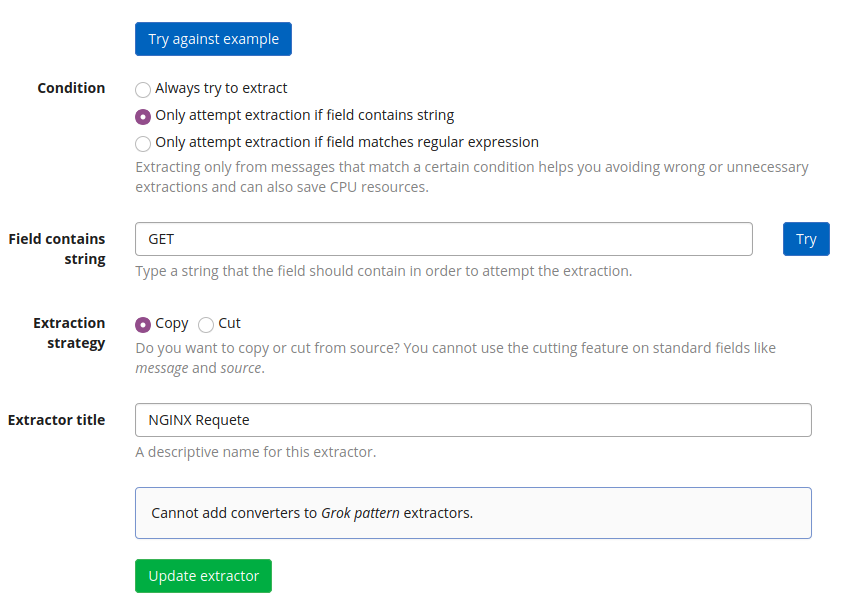
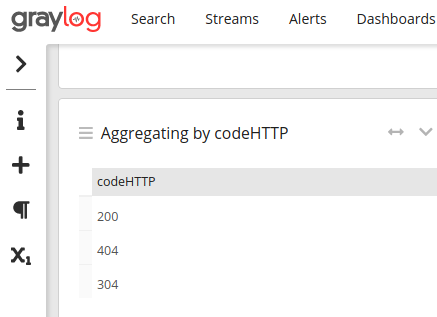
On valide et nous pouvons extraire facilement des données à partir des trames.
Par exemple, la liste des codes http retournés dans l'ensemble des trames:
Quelques options pour la configuration de l'extracteur (extractor)
Si c'est un peu chargé au niveau des champs, il est possible de ne pas prendre en compte certain champ avec le mot clé unwanted.
Ca donne par exemple:
<%{BASE10NUM:UNWANTED}>%{MONTH:UNWANTED} %{MONTHDAY:UNWANTED} %{TIME} %{HOSTNAME} %{WORD:Service}: %{IP:srcIP} - - \[%{HTTPDATE:timestamp}\] "GET %{URIPATH} HTTP/%{NUMBER:httpversion}" %{BASE10NUM:codeHTTP} %{BASE10NUM:bytes} "%{URI}" "%{GREEDYDATA:Navigateur}"